hdfs文件系统笔记总结
关于HDFS原理在此写个总结
前三点主要围绕分布式文件系统那么多,为什么apache还要开发自己的文件系统
后两点主要围绕hdfs的高可用问题
1.HDFS存储模型
- 1.hdfs的存储模型第一个核心为block(块),hdfs的所有存储文件都是按照块来进行划分的,每个文件可以有不同的块,但是文件中除了最后一个块,每个块的大小必须相同,这个为了保证可以和hadoop计算框架,相适应能够有一个统一的计算单位,这个统一的计算单位block不是固定的,需要根据具体的I/O特性进行调整.
- 2.除了围绕块之外存储模型还有一个核心是存储副本(replication),副本可以冗余数据保证系统的可靠性.并多个副本存储在不同主机当中可以增加计算程序与数据在同一集群的概率,提升计算的性能.
2.HDFS的角色
HDFS主要角色
主要角色有两个namenode和datanode,主要功能包括如下:
- 1.namenode主要维护文件的元数据
- 2.datanode主要维护负责block的读和写
- 3.datanode会与namenode维持心跳,并汇报自己持有的block信息和列表
- 4.clinet向Namenode交互文件元数据.和datanode交互文件blocks数据
次要角色:SecodaryNamenode
要聊SecondaryNamenode就需要先知道Namenode是如何持久化元数据文件的
首先,NameNode维护元数据是在内存中,如果机器突然宕掉,如果不把元数据写在磁盘上,那时没有办法恢复的,元数据会永久丢失
目前持久化有两种方式:
- 1.通过操作日志文件(EditLog)恢复,也就是每当NameNode有一条对元数据的操作,就会增加一条日志,但是这样的方式有两个缺点,第一随着运行时间的增长,NN的log会变得及大,很浪费磁盘空间,第二点也是运行时间长的话,要恢复需要很长时间,比如这台机器运行了十年,宕掉之后可能机器需要五年的时间恢复.
- 2.通过内存的快照(fsImage)恢复,就是将某个时间点的内存状态溢写到磁盘上,但这种方式没办法实时的保存,磁盘IO是有瓶颈的,我们不可能隔一两分钟就保存内存的镜像
而NameNode保存选择了一个折衷的方式来规避两者明显的缺点:
每相隔一个时间点,将Editlog里面的操作写入到fsImage当中,合并成为一个新的fsImage,然后将在之前产生旧EditLog,只保留最近fsImage时间点之后产生EditLog删掉,这样让fsImage滚动更新的方法,使得占少量的磁盘的情况下,能让NN恢复到机器宕掉那一刻的状态.
但是如果把这个保存合并快照的工作全都的交给Namenode的话,此节点的压力会很大,所以关于fsImage的滚动合并工作便交给另一个工作节点SecondaryNamenode来执行
3.角色交互产生的机制
安全模式
每次NN启动的时候,都会将最近时间点的fsImage加载进来,然后将EditLog操作合并到系统内存当中,最后将新的fsImage写入,并删除EditLog
NN会文件的属性作为元数据,但不包括datanode列表,
主要是为了防止
NN重启后,DN(DataNode)列表中,有启动不起来DN,此时正好有客户端请求,NN返回了不可靠的DN列表
这样的情况发生
所以NN,在重启后,会接受所有DN心跳信号和状态报告.
当确定NameNode检测某个数据块的副本达到最小值,那么他会被认为副本安全的,当有一定百分比的数据被确认是安全后,NameNode将会退出安全模式.
副本放置策略
第一个副本放置在本机,第二个副本放在不同机架,第三副本放置在同一机架,之后的副本随机.
原因:
- 为了能在程序计算的时候找到最近的block数据
- 为了能在机架损毁的时候仍然能保留其完整的
HDFS写流程
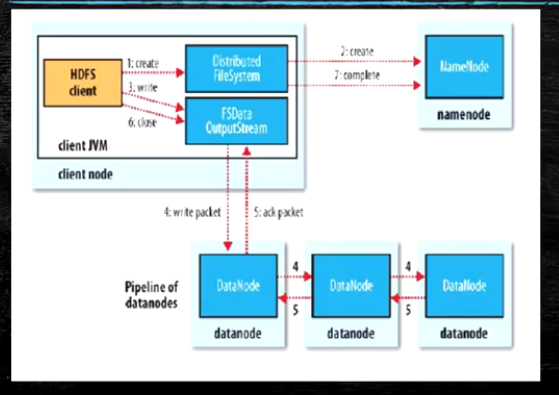
- Client与NN创建连接
- NN建立元数据
- NN验证元数据是否合理
- NN触发副本放置策略,返回DN列表
- Clinet将数据块分割为64K数据,并使用chunk(512B)和sumchunk进行填充
- Clinet向DataNode发送数据块,第一个DN受到packet后本地保存发送到第二个DN
- 第二个DN发送到第三个DN
- 当block传输完成,DN分别向各NN汇报,同时Client继续传输下一个block
- 所以client和block汇报也是并行的
- 数据分割是为了保证DN可以在第一个数据包发送完成之后,可以立刻发送给第二个DN,保证传输效率以及传输的一致性,并且这样传输,对客户端来说是透明,客户端只要保证给第一个DataNode传输完整数据就可以.
HDFS读流程
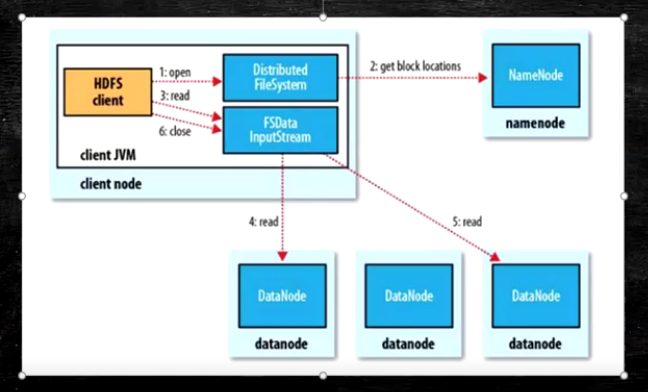
- 为了降低整体的带宽消耗和读延迟,HDFS会尽量让读取程序读取离他最近的副本
- 如果再读取程序的同一个机架上有一个副本,那么就读该副本
- 如果一个HDFS集群跨越多个数据中心,那么客户端也将首先读本地数据中心的副本
- 语义:
download a file
Client和NN交互文件元数据获取fileBlockLocation
NN按距离策略排序返回
Client尝试下载Block并且校验数据完整性(校验盒校验) - 语义:下载一个文件其实是获取文件的所有的Block元数据,那么子集获取block应该成立
Hdfs支持Client输出文件的offset自定义连接哪些Block的DN,自定义获取数据
这个是支持计算层的分治,并行计算的核心(牢记)
5.HDFS设置高可用
为什么
为了提升NN的可靠性,如果集群当中只有一个NN,那么在某些情况下Namenode宕机,那么整个集群就不可用了,所以为了提升整个集群的可用性,我们设置两个NN,一主一备,确保主NN宕掉之后,备用NN能启动起来.
开始实现
要想让两个NN能够无缝切换,我们必须先实现两个进程的内存同步,有两种方法进行两个机器的进程同步:
- 阻塞同步,就是需要同步数据的时候,主NN进入阻塞状态,等待备用NN同步完毕,然后继续运行,但是在现实生产生活中,这种方式显然是行不通的,我们保证了两个NN的强一致性,但是主NameNode的可用性却大大降低了,也就是Namenode同步数据的时候,我们无法使用这个NN.
- 非阻塞异步,就是主NN需要同步数据时直接发给备用NN,同时NN保持运行接受客户端请求,等待备用NN同步完毕回调通知主NN.但是这样NN的一致性就无法保证
CAP定理
说到这么不得不谈谈CAP定理,即一致性(Consistency),可用性(Avalible),分区容错性(Partition tolerance)三者只可满足其二
- 分区容错性,当分布式系统中遇到任何网络分区故障时,仍然需要能够保证对外提供满足一致性和可用性的服务,除非整个网络发生故障,通俗一点说,我将数据副本设置到多个节点上,其中一个节点故障了,因为其他节点持有数据副本,仍能对外保持可用一致的服务,我称这个分布式系统具有分区容忍性.
- 可用性,是指系统提供的服务必须一直处于可用的状态,对于每一个从操作请求总是能够在有限的时间内返回结果.
- 一致性,指的是数据在多个副本之间能够保持一致的特性,在一致性的需求下,当一个系统在数据一致的状态执行更新操作后,应该保证系统为数据仍然处于一致的状态
CAP套用分析
我们套用CAP定理再回顾一下之前NN的同步的两种方法,
- 两个方法都满足分区容忍性,
- 第一个阻塞同步方法,会影响可用性,导致系统没办法在系统规定时间内返回正确的响应结果,
- 第二个异步非阻塞方法,没有办法保证一致性,异步回调没有办法保证备用的NN能完全将数据保持同步一致.
折衷办法:最终一致性
既然CAP没办法全部满足,那么我们能不能选择一个折衷的方法呢?
当然有,NN就是使用这种方法,即通过Poxas选举算法保持数据的最终一致性
首先,添加一个角色较jounralNode,当NN的命名空间有任何修改时,会告知大部分的JounralNodes进程,standby状态的NN会读取JNs中的信息,并监控EditLog的变化,把变化与应用于自己的命名空间.
那如何保证数据的一致性呢?
JounralNode一般会大于等于3的基数个,首先JounralNode根据少数服从多数的原则,选择出其中的Leader,Leader只有一个,它负责记录自己和其他的JounralNode是否接受到NameNode的变更信息,超过半数的JounralNode接收到NN的变更信息时,才承认作数据同步是可靠的.通知备用的NN读取JounralNode的信息.这样我们即保证了可用性,也保证了数据同步的最终一致性(弱一致性)
zookeeper分布式协调系统自动切换
上面我们解决的NN之间的数据同步问题,但是现实是active的NN出现故障的时候,我们只能手动其切换NN,所以我们还需要zookeeper的帮助.
新增角色ZK(zookeeper)和ZKFC(ZookeeperFailOver)
当我们启动zookeeper进程的时候,会有两个进程监控我们的NN,一个是zookeeper本身的进程,和JounralNode有着相似的选举算法,也是进程数必须超过zookeeper的奇数倍,zkfc要与zk进程保持心跳,而zkfc主要负责监控和切换主备的Namenode
自动主备切换流程详述
- 启动两个NN进程,此时两个NN都处于备用的状态
- 启动zk进程和zkfc进程,当zk进程启动之后,zkfc进程争相在最近的zk进程上建立节点(抢锁),第一个成功建立节点的zkfc进程会将它操控的NN设置为Active,另一个就会被定义为standby
- 假如zkfc挂掉了,zk进程监控不到zkfc的心跳,会将在zkfc建立的节点删掉,而监控standby的zkfc进程看到zk上的节点消失了,会主动建立节点,并先将active的NN节点降级为standby,自己监控的NN节点升级为active
- 假如active的NN挂掉了,zkfc进程检测到会删除在zk上建立的节点,而监控standby的zkfc会在zk上建立节点,并测试连接另一个NN是否宕掉,最后将自己监控的NN升级为Active
- 有一种特殊情况是,Active的NN可以运行可以和DataNode连接,但就是连接不上其他人主机的zkfc,当这个NameNode挂掉的时候,其他zkfc会一直处于阻塞状态,不断的尝试连接挂掉的NN,此时需要检查一下网卡硬件的问题