spark源码分析RPC篇-1
spark-core源码分析01(RPC环境)
本篇源码分析,主要就Spark Standlone(spark2.3.4版本)资源管理的RPC调用部分进行总结
RPC调用概述
RPC调用其实并不是很高深,它特指某类通信技术,它的应用其实特别广泛,我们经常所说的http协议也是一种特殊RPC调用,http协议就定义了请求的方式方法post,get,delete,update
而通过看源码我们会发现,spark中Master和Worker之间也定义了相似的消息投递规则即send,ask,recive,reciveAndReply
RPC的原理很简单,但是落地到实际生产环境中需要做的细活很多,比如拆包粘包问题,动态代理库的使用,线程池,链接池,传输层的封装等等
这里简单给出RPC框架的简单架构
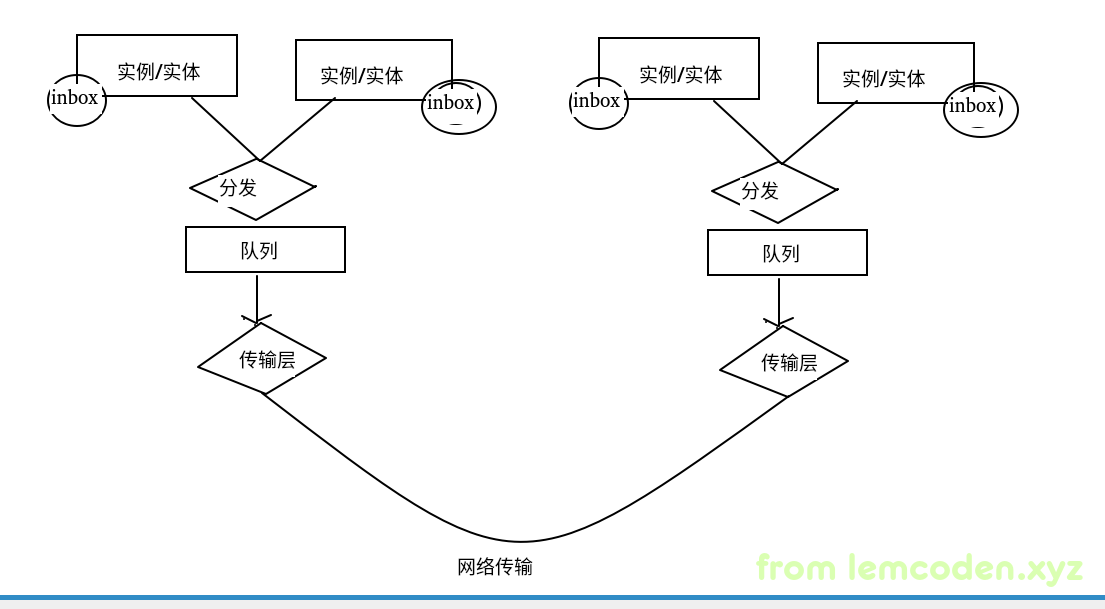
client将实体类封装为inbox通过分发器分发到队列当中,然后传输层连接池,线程池拉取队列数据,通过网络发送二进制数据
server端按照client端数据反向操作
从shell脚本开始追踪
源码文件这个不用说直接从github下载下来就可以,我下载的是基于2.3.4版本的spark,比较经典
下载完成之后导入到IDEA当中
那么从哪里开始呢?我们需要个开始,我们从shell启动脚本开始,里面一定有java的启动类,首先从start-all.sh开始,下面是伪代码
1 | # Load the Spark configuration |
分别调用start-master.sh和start-slaves.sh(start-slaves.sh 中启动了 start-slave.sh)接下来我们看一下Master里面有什么
在个start-master.sh 这个shell脚本当中我们分别看到了两个java 类路径,分别是
1 | CLASS="org.apache.spark.deploy.master.Master" |
简单的端点对象
那我们看java源码就直接从此处入手,在java源码中找到spark-core 这个module,然后根据包我们首先找到了Master类
1 | private[deploy] class Master( |
首先看我们的参数,其中就有一个RPCEnv,即Master进程的RPC调用环境,然后Master本身继承自
ThreadSafeRpcEndpoint
安全的RPC线程调用的端点,我们向上回溯Master到它的顶级父类RpcEndpoint
这个就是对所有RPC角色的抽象,在spark中所有要进行RPC调用的角色进程都要实现这个类
我们浏览一下其中的方法,除了必要的onConnect,onDisconnect,onNetworkError
还有两个比较特殊的方法即
1 | /** |
这两个方法是主要的,端点类通过这两个方法接受数据
有了接收数据的方法,必定有发送数据的方法,我们从上面方法的注释当中发现对应的发送方法
RpcEndpointRef.send
RpcEndpointRef.ask
我们看到后面跟了一个后缀,即Ref(Reference的缩写),这就像我们Java中的对象一样,我们new一个对象就会产生一个引用给我们的变量赋值,而实际真正的对象是在jvm的堆存储结构当中,同理RPC环境中,作为客户端我们持有一个端点的引用,用来发送信息,而实际真正的端点是在服务器当中,用来接受,反馈信息.
RPC通信环境
好的,先收,我们从Master的main入口方法开始研究
-
main方法
1
2
3
4
5
6
7
8
9def main(argStrings: Array[String]) {
Thread.setDefaultUncaughtExceptionHandler(new SparkUncaughtExceptionHandler(
exitOnUncaughtException = false))
Utils.initDaemon(log)
val conf = new SparkConf
val args = new MasterArguments(argStrings, conf)
→ val (rpcEnv, _, _) = startRpcEnvAndEndpoint(args.host, args.port, args.webUiPort, conf)
rpcEnv.awaitTermination()
}
在main方法中我们重点关注startRpcEnvAndEndpoint,我们主要观其RPC的环境是如何启动的
-
startRpcEnvAndEndpoint
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18/**
* Start the Master and return a three tuple of:
* (1) The Master RpcEnv
* (2) The web UI bound port
* (3) The REST server bound port, if any
*/
def startRpcEnvAndEndpoint(
host: String,
port: Int,
webUiPort: Int,
conf: SparkConf): (RpcEnv, Int, Option[Int]) = {
val securityMgr = new SecurityManager(conf)
→ val rpcEnv = RpcEnv.create(SYSTEM_NAME, host, port, conf, securityMgr)
val masterEndpoint = rpcEnv.setupEndpoint(ENDPOINT_NAME,
new Master(rpcEnv, rpcEnv.address, webUiPort, securityMgr, conf))
val portsResponse = masterEndpoint.askSync[BoundPortsResponse](BoundPortsRequest)
(rpcEnv, portsResponse.webUIPort, portsResponse.restPort)
}
有rpcEnv的创建方法,创建完之后,会把Master作为EndPoint注册到RPC环境当中,但是有个问题
Master好像没有执行?也就是说它并没有作为端点来调用recive或者reciveAndReply方法来传输数据?
我们记住这个问题,继续往下走,后面会聊到.
我们先来看以下RpcEnv对象里面有什么
点进create方法,盯着代码看几秒
-
create
1
2
3
4
5
6
7
8
9
10
11
12
13def create(
name: String,
bindAddress: String,
advertiseAddress: String,
port: Int,
conf: SparkConf,
securityManager: SecurityManager,
numUsableCores: Int,
clientMode: Boolean): RpcEnv = {
val config = RpcEnvConfig(conf, name, bindAddress, advertiseAddress, port, securityManager,
numUsableCores, clientMode)
→ new NettyRpcEnvFactory().create(config)
}
发现是通过工厂模式返回了NettyRpcEnv的对象,那我们再具体看看子类对象有什么
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
def create(config: RpcEnvConfig): RpcEnv = {
val sparkConf = config.conf
// Use JavaSerializerInstance in multiple threads is safe. However, if we plan to support
// KryoSerializer in future, we have to use ThreadLocal to store SerializerInstance
→ val javaSerializerInstance =
new JavaSerializer(sparkConf).newInstance().asInstanceOf[JavaSerializerInstance]
val nettyEnv =
→ new NettyRpcEnv(sparkConf, javaSerializerInstance, config.advertiseAddress,
config.securityManager, config.numUsableCores)
if (!config.clientMode) {
→ val startNettyRpcEnv: Int => (NettyRpcEnv, Int) = { actualPort =>
nettyEnv.startServer(config.bindAddress, actualPort)
(nettyEnv, nettyEnv.address.port)
}
try {
→ Utils.startServiceOnPort(config.port, startNettyRpcEnv, sparkConf, config.name)._1
} catch {
case NonFatal(e) =>
nettyEnv.shutdown()
throw e
}
}
nettyEnv
}
}
spark做RPC传数据数据时,序列化器使用的是标准的Java序列化器,因为代码算是比较旧了,估计新的版本真如注释所说,改成了Kryo序列化器,不过这个我们只要知道搭建RPC架构时,序列化部分是必不可少的就可以
我们看到下面new一个NettyRpcEnv,然后再下面一句需要注意的一点是,startNettyRpcEnv这个变量是一个函数,我们看到它的类型是用函数字面量表示的,也就是说,它并不会立即执行,而是作为变量传到startServiceOnPort方法当中,等待在将来的某一时刻调启,而startServiceOnPort方法执行,就意味着此刻的传输层服务就已经启动了
然后我们粗略的看一下NettyRpcEnv对象中,有两个主要的变量,对应我们最开始所画出的两个角色
一个是dispatcher分发器,另一个是transportServer传输层服务
传输层技术
分发器等一下再说,我们先看一下transportServer长什么样子,点进去,直接看init方法
1 | private void init(String hostToBind, int portToBind) { |
因为代码过多,所以这里进行了删减,看到这里做过Netty开发的同学一定觉得亲切且熟悉(其实笔者对这方面理解还很浅显,回头会专门出一篇博客,熟悉一下Netty)
原来Spark所用的传输层技术,也是我们常用的Netty框架.
走到这里,我们先停一停,思考一下,代码中有一个createEventLoop方法,重点是Loop这个单词,它是轮询的意思,也就是说,我们一看到带Loop这个字眼的对象,就条件反射知道这对象中一定藏着类似while(true)的循环逻辑,让线程阻塞住,不断的接收或者拉取数据
然后,往下走有个channel方法,这个聊一聊,我们都知道linux是使用文件描述符进行IO操作(广义上的不仅仅指磁盘IO),文件描述符不仅可以读,还可以写,但是最开始的java的IO框架不一样,他必须分为输出流和输入流,但是java依赖于JVM,JVM又依赖于操作系统,之后JVM 的NIO 框架当中,就出现了既可读又可写的Channel,从某些方面来说java反璞归真了.
最后我们看最下面的,childHandler方法,我们需要通过Handler类来处理和接收数据,我们进入initalizePipeline方法.里面有createChannelHandler方法
1 | createChannelHandler(channel, channelRpcHandler); |
再进入
1 | private TransportChannelHandler createChannelHandler(Channel channel, RpcHandler rpcHandler) { |
我们看到了有请求的handler也有响应的,然后再进入TransportChannelHandler,有一个channelRead方法,
1 |
|
再进入handle.rquestMessage的方法
1 |
|
再进入processRpcRequest方法
1 | private void processRpcRequest(final RpcRequest req) { |
再进入receive方法(NettyRpcHandler中)
1 | override def receive( |
哎??我们看到了dispatcher,也就是说RPC环境当中服务端接收到请求信息的时候,会首先交给dispatcher进行分发,这正好对应我们刚开始的架构
接下来就postRemoteMessage一路向下点,点到最后dispatcher的postMessage
1 | private val endpoints: ConcurrentMap[String, EndpointData] = |
我们看到endpoints,这是一个ConcurrentHashMap,并发的哈希表结构,这个JDK的包的源码(JUC)值得一看,不过本篇博客主要目的在于通过源码讲述RPC的主脉络,也不多做拓展
我们通过端点名字获取端点对象,并通过inbox信箱投递消息(投递可没有发送的意思,inbox其实维护了一个集合,我们将message信息添加到这个集合里面).
然后是recivers,这是一个队列,我们接收到的消息,会封装成EndPointData最终通过分发器,分发到队列里面.
那我们什么时候从队列中拿这个EndPointData呢?
这个问题,我们先保留,因为这个需要从另一条源码路径进行分析才能得到答案.
端点注册
在讲另一条源码脉络之前,我们先回溯之前看到的源码,根据以上一条的脉络分析我们得出以下几点
- Master是一种EndPoint
- RpcEnv由主要由dipatcher分发器和server: TransportServer传输层服务组成
- 传输层服务默认由Netty(RpcEnv默认也是NettyRpcEnv)实现,并且接收信息后,会交给dispatcher分发
- dipatcher会把字节类型的信息放到inbox信箱中,然后再封装进EndPoint,放到本地的队列里面等待被拿起
好了,我们再回到最开始的方法即,Master main中的startRpcEnvAndEndpoint方法
-
startRpcEnvAndEndpoint
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19/**
* Start the Master and return a three tuple of:
* (1) The Master RpcEnv
* (2) The web UI bound port
* (3) The REST server bound port, if any
*/
def startRpcEnvAndEndpoint(
host: String,
port: Int,
webUiPort: Int,
conf: SparkConf): (RpcEnv, Int, Option[Int]) = {
val securityMgr = new SecurityManager(conf)
val rpcEnv = RpcEnv.create(SYSTEM_NAME, host, port, conf, securityMgr)
→ val masterEndpoint = rpcEnv.setupEndpoint(ENDPOINT_NAME,
new Master(rpcEnv, rpcEnv.address, webUiPort, securityMgr, conf))
val portsResponse = masterEndpoint.askSync[BoundPortsResponse](BoundPortsRequest)
(rpcEnv, portsResponse.webUIPort, portsResponse.restPort)
}
进入到注册方法中,发现是个抽象类,唯一实现的是NettyRpcEnv继续往下追踪,发现
1 | override def setupEndpoint(name: String, endpoint: RpcEndpoint): RpcEndpointRef = { |
这边写了一个分发器在里面,我们继续往下走
1 | def registerRpcEndpoint(name: String, endpoint: RpcEndpoint): NettyRpcEndpointRef = { |
这里就有要说明的地方了,这里的nettyEnv.address是直接输入了,其实一般的RPC调用框架都会给地址封装一层注册中心,注册发现的一个功能,但是这里为什么没做呢?问题很简单,因为spark的RPC调用环境中就Master和Worker俩角色,不像其他的RPC的环境,节点很多,且可能发生变动.(PS:聊一些题外话,一些军方的后台项目,都是直接用servlet进行的开发,而不是Spring这些,因为Spring也是封装的servlet,直接用servlet做开发,代码的调用路径最短,实际运行效率是最高的),所以有些时候不能为了架构而架构,为了需求而架构.
接下来的步骤是将Master的EndPoint对象封装到EndPointData里,并加入到receviers的队列当中.
角色启动
我们来看一下EndPointData里面是什么,先进入构造方法
1 | private class EndpointData( |
一个EndPointData当中会对应new一个inbox,并且把EndPoint,EndPointRef对象放到inbox当中.
我们再看信箱当中,重点是同步的代码块
1 | protected val messages = new java.util.LinkedList[InboxMessage]() |
Inbox在new的时候,会在消息链表(注意这个不是dispatcher里面的消息队列)当中添加一个OnStart消息,这个消息是什么?
1 | private[netty] case class OneWayMessage( |
到这里我们看到,这个消息仅仅是一个样例类,用来和其他消息做区分,那这个消息怎么做的处理?
我们看Inbox的procees方法
1 | def process(dispatcher: Dispatcher): Unit = { |
这里会对消息类型进行匹配,不得不说一句,scala语法真是好,如果这里换成Java的话,肯定一堆的if else instanceof 的判断.
那么,匹配到OnStart方法,会执行endPoint的onStart的方法…等等!!!
Master就是一种EndPoint的,那么…
1 | private[deploy] class Master .... |
果然,Master中有onStart方法的实现,也就是说当我们new一个EndPointData的时候,会new一个Inbox,而Inbox在new的时候,会默认投递一个OnStart消息,这个消息处理时,会调用EndPoint的OnStart方法启动相应的角色
好了,分析到这里,我们的问题好像还有一个问题没解决,对!我们只是往队列里面塞数据了,什么时候拿给inbox做的处理?
首先我们知道,所有的配置设置都已经完成,随着RpcEnv的创建,他的成员Dispacher,TransportServer也跟着一起创建,并且传输层服务已经启动,Master已经作为Endpoint注册到Dispathcer当中并且预埋了启动逻辑.
线程池的启动
那么我们再回头细看一下Dispatcher这个对象,发现了一个线程池创建,执行方法
1 | private val threadpool: ThreadPoolExecutor = { |
线程池启动的线程数的逻辑这里就不再多说了,重点在于,它会启动线程数个MessageLoop线程,上面已经说过,凡是带Loop的绝对中间有While(true)的轮询逻辑,我们这里就细看一下
1 | /** Message loop used for dispatching messages. */ |
最后就是这里,Dipatcher在创建的时候就创建了线程池,并且线程池当中执行着的都是无限轮询着从消息队列中拉取并处理的Loop线程.这就解答了我们开始的问题———-是谁拿了消息队列里的消息?
好了,现在Spark中Rpc环境的基本角色,以及他们的调用链路已经介绍清楚了.下一篇博客见,Bye,Bye